EasyAnimate: A High-Performance Long Video Generation Method based on Transformer Architecture

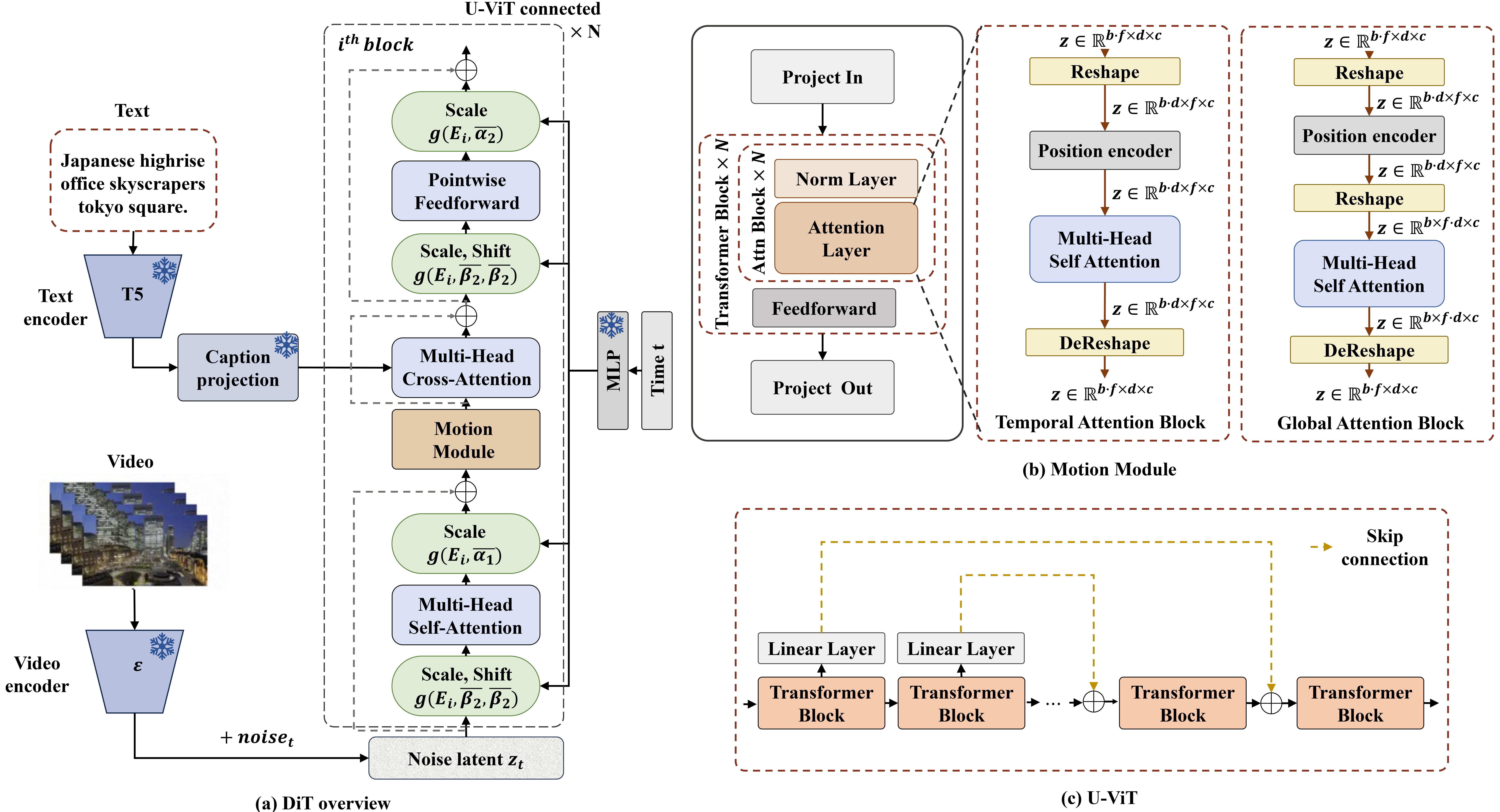
Methodology
EasyAnimate is a pipeline based on the transformer architecture that can be used to generate AI photos and videos, train baseline models and Lora models for the Diffusion Transformer. We support making predictions directly from the pre-trained EasyAnimate model to generate videos of about different resolutions, 6 seconds with 24 fps (1 ~ 144 frames, in the future, we will support longer videos). Users are also supported to train their own baseline models and Lora models to perform certain style transformations.
Gallery
Here we demonstrate some videos generated by EasyAnimateV3. This is the part of image to video.
Click to Play the Videos.
Examples of Persons:
Examples of Animals:
Examples of Fire:
Result of 576x1008 resolution
Examples of Water:
Examples of Painting:
Examples of Something:
This is the part of text to video.
Click to Play the Videos.
Project page template is borrowed from AnimateDiff.